Bạn đang có ý định mua một chiếc laptop mới và băn khoăn không biết mức giá hợp lý cho một thiết bị có cấu hình mong muốn là bao nhiêu? Việc tìm kiếm thông tin trên hàng ngàn trang web hay ghé thăm các cửa hàng vật lý có thể tiêu tốn rất nhiều thời gian và công sức. Đối với những người yêu công nghệ nhưng không có nhiều thời gian rảnh rỗi, giải pháp thủ công này thực sự không mấy hấp dẫn. Bài viết này sẽ hướng dẫn bạn cách sử dụng mã Python và một chút kiến thức về hồi quy tuyến tính để xây dựng một công cụ dự đoán giá laptop hiệu quả, giúp bạn dễ dàng đưa ra quyết định mua sắm thông minh hơn.
Tại sao cần xây dựng công cụ dự đoán giá laptop?
Thị trường laptop hiện nay vô cùng đa dạng với hàng ngàn mẫu mã và cấu hình khác nhau. Việc tự mình tổng hợp và so sánh tất cả thông tin này để đưa ra mức giá hợp lý là một nhiệm vụ bất khả thi. Bạn sẽ cần một chương trình có khả năng nhập các thông số kỹ thuật mong muốn, ví dụ như dung lượng RAM hay độ phân giải màn hình, và tự động đưa ra ước tính về giá.
Mục tiêu của chúng tôi không chỉ là tạo ra một công cụ hữu ích cho bản thân mà còn muốn chia sẻ nó với những độc giả khác đang tìm kiếm một chiếc laptop mới. Ai cũng muốn tránh việc trả quá nhiều tiền cho một thiết bị. Với kiến thức về hồi quy tuyến tính từ môn thống kê, chúng tôi nhận thấy có thể dễ dàng xây dựng một mô hình để trả lời những câu hỏi này. Python, với sự đơn giản và các thư viện mạnh mẽ cho phân tích dữ liệu, là lựa chọn lý tưởng cho dự án này. Ngôn ngữ này đã trở nên phổ biến trong khoa học dữ liệu, cho phép cả những người không có nền tảng khoa học máy tính chuyên sâu cũng có thể tiếp cận và khai thác sức mạnh của nó.
Chuẩn bị bộ công cụ thống kê Python
Để thực hiện dự án này, chúng tôi đã sử dụng các thành phần quen thuộc trong hệ sinh thái thống kê của Python. Để tránh xung đột với các phiên bản Python khác trên hệ thống, việc tạo một môi trường riêng biệt là rất quan trọng. Mamba (hoặc VirtualEnv) là một công cụ tuyệt vời cho việc này.
Thành phần đầu tiên không thể thiếu là NumPy (numpy.org). Đây là thư viện phổ biến cho mọi loại phép toán số học, đặc biệt là các tính toán thống kê và đại số tuyến tính sẽ được thực hiện ngầm trong mô hình.
Tiếp theo là thư viện Pandas (pandas.pydata.org), cho phép bạn nhập tập dữ liệu và xem nó dưới dạng các cột, hay còn gọi là “data frame”. Nó giống như sự kết hợp giữa cơ sở dữ liệu quan hệ và bảng tính, cung cấp khả năng thao tác dữ liệu mạnh mẽ.
Seaborn (seaborn.pydata.org) là thư viện dùng để trực quan hóa dữ liệu thống kê. Chúng tôi sử dụng nó để hiển thị phân phối dữ liệu qua biểu đồ histogram, biểu đồ tán xạ và biểu đồ hồi quy tuyến tính.
 Biểu tượng Seaborn với đồ thị trực quan hóa dữ liệu bằng Python, minh họa khả năng khám phá và hiển thị dữ liệu thống kê phức tạp.
Biểu tượng Seaborn với đồ thị trực quan hóa dữ liệu bằng Python, minh họa khả năng khám phá và hiển thị dữ liệu thống kê phức tạp.
Cuối cùng, Pingouin (pingouin-stats.org) giúp chúng tôi dễ dàng thực hiện nhiều kiểm định thống kê mà không cần phải ghi nhớ mọi công thức phức tạp. Đây chính là công cụ sẽ xây dựng mô hình thông qua hồi quy tuyến tính đa biến, so sánh giá bán lẻ với tất cả các thuộc tính của laptop.
Việc cài đặt và kết hợp tất cả các thư viện này khá đơn giản trong hầu hết các môi trường giống Unix, bao gồm cả Windows khi sử dụng Windows Subsystem for Linux (WSL). Bạn có thể tham khảo hướng dẫn trên trang web để cài đặt WSL.
Jupyter Notebook (howtogeek.com/how-to-get-started-creating-interactive-notebooks-in-jupyter/) cung cấp một cách tương đối thân thiện để chạy các lệnh Python, xem kết quả và lưu trữ chúng. Mặc dù không bắt buộc, nhưng nó làm cho quá trình phát triển và trình bày mã trở nên thuận tiện hơn rất nhiều. Chúng tôi đã tạo một Jupyter Notebook cho dự án này và các ví dụ mã sẽ được trình bày từ đó. Bạn có thể xem mã đầy đủ và các ví dụ chi tiết hơn trên GitHub của chúng tôi tại github.com/ddelony/stats/blob/main/laptop_prices.ipynb.
Với Mamba đã được cài đặt, bạn có thể tạo môi trường cần thiết. Để kích hoạt môi trường đã chuẩn bị sẵn, chúng tôi sử dụng lệnh sau trong terminal Linux:
mamba activate statsThu thập dữ liệu laptop
Để xây dựng tập dữ liệu cho mô hình hồi quy, việc tự mình tìm kiếm trên các cửa hàng trực tuyến và xây dựng một cơ sở dữ liệu toàn diện sẽ tốn rất nhiều thời gian, chưa kể đến việc làm sạch dữ liệu để đảm bảo tính nhất quán. May mắn thay, đã có người khác thực hiện công việc này.
Một cơ sở dữ liệu về laptop với các thông số kỹ thuật phần cứng như tốc độ CPU, dung lượng RAM, dung lượng lưu trữ, và độ phân giải màn hình (chiều ngang và chiều dọc) đã có sẵn trên Kaggle (kaggle.com/datasets/owm4096/laptop-prices).
Giá của các laptop trong dữ liệu gốc được tính bằng Euro. Tuy nhiên, một kiểm tra nhanh trên Xe.com vào tháng 7 năm 2025 cho thấy tỷ giá hối đoái giữa Euro và đô la Mỹ khá gần nhau, nên việc chuyển đổi không ảnh hưởng đáng kể đến mô hình.
Xây dựng mô hình hồi quy dự đoán giá laptop
Với môi trường đã được thiết lập và dữ liệu đã thu thập, đã đến lúc xây dựng mô hình. Đầu tiên, chúng ta cần nhập các thư viện sẽ sử dụng:
import numpy as np
import pandas as pd
import seaborn as sns
%matplotlib inline
import pingouin as pgCác dòng này nhập các thư viện NumPy, Pandas, Seaborn và Pingouin, được rút gọn thành “np”, “pd”, “sns” và “pg” để tiện sử dụng. Dòng bắt đầu bằng “%” được dùng trong Jupyter Notebook để yêu cầu thư viện Matplotlib (mà Seaborn sử dụng) hiển thị các biểu đồ trực tiếp trong notebook. Nếu không, chúng sẽ được hiển thị trong một cửa sổ riêng.
Tiếp theo, chúng ta sẽ nhập dữ liệu bằng Pandas:
laptops = pd.read_csv("data/laptop_prices.csv")Lệnh này sẽ tạo ra một Pandas DataFrame. Chúng ta có thể xem cấu trúc dữ liệu được bố trí như thế nào bằng phương thức head():
laptops.head()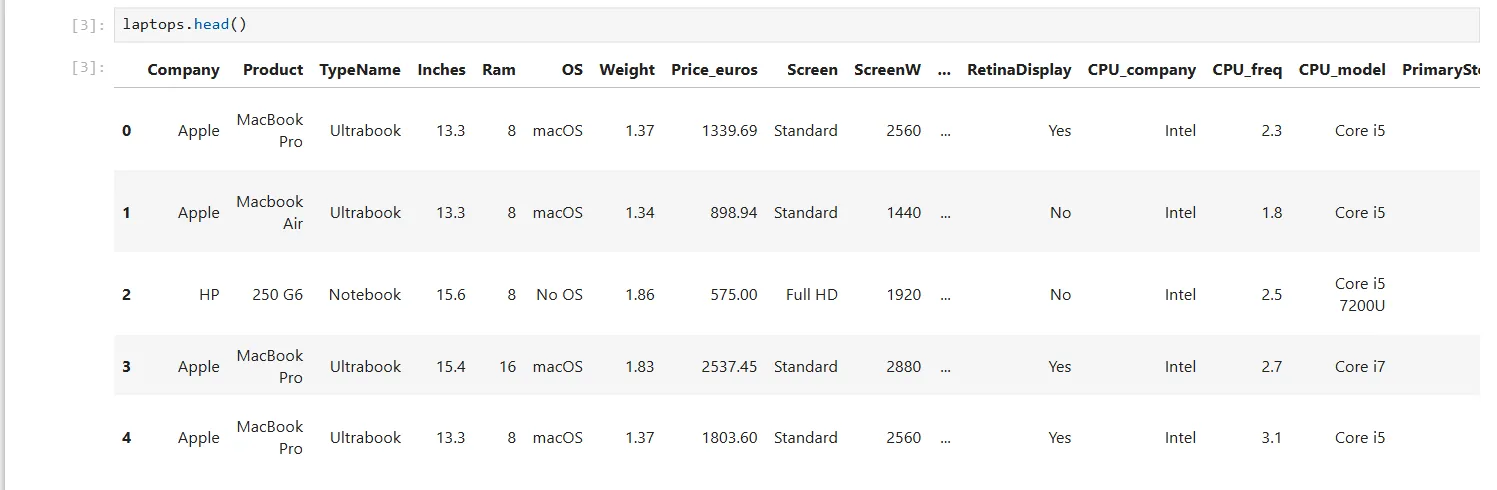 Ảnh chụp màn hình kết quả lệnh laptops.head() trong Jupyter Notebook, hiển thị năm dòng đầu tiên của bảng dữ liệu laptop bao gồm các thông số và giá.
Ảnh chụp màn hình kết quả lệnh laptops.head() trong Jupyter Notebook, hiển thị năm dòng đầu tiên của bảng dữ liệu laptop bao gồm các thông số và giá.
Chúng ta cũng có thể xem các thống kê mô tả cơ bản của tất cả các cột số bằng phương thức describe():
laptops.describe()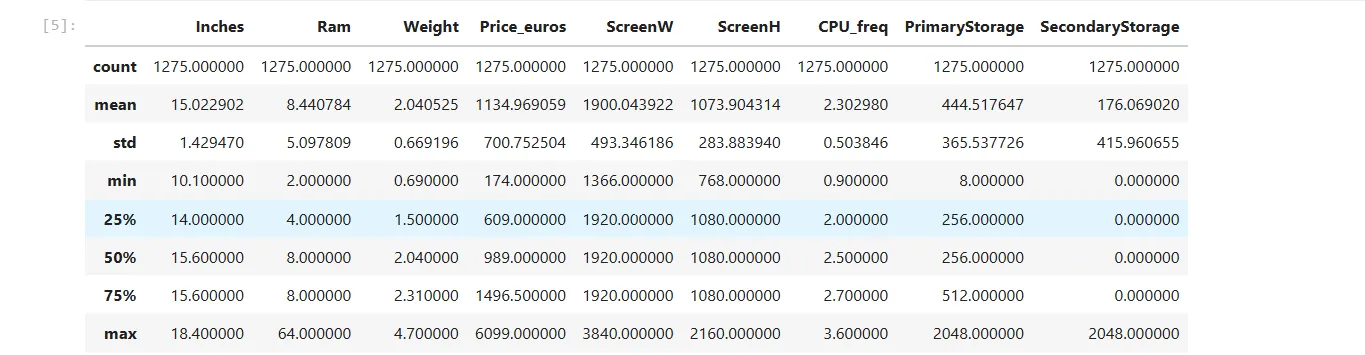 Bảng thống kê mô tả chi tiết các thuộc tính số của tập dữ liệu laptop, hiển thị giá trị trung bình, độ lệch chuẩn, min, max và các phần tư.
Bảng thống kê mô tả chi tiết các thuộc tính số của tập dữ liệu laptop, hiển thị giá trị trung bình, độ lệch chuẩn, min, max và các phần tư.
Phương thức này sẽ hiển thị giá trị trung bình, trung vị, độ lệch chuẩn, giá trị tối thiểu, tứ phân vị dưới (phân vị 25), tứ phân vị trên (phân vị 75) và giá trị tối đa của mỗi cột.
Chúng tôi cũng muốn trực quan hóa phân phối dữ liệu thông qua biểu đồ histogram. Hàm displot của Seaborn sẽ giúp thực hiện điều này. Để xem phân phối giá laptop:
sns.displot(x='Price_euros',data=laptops)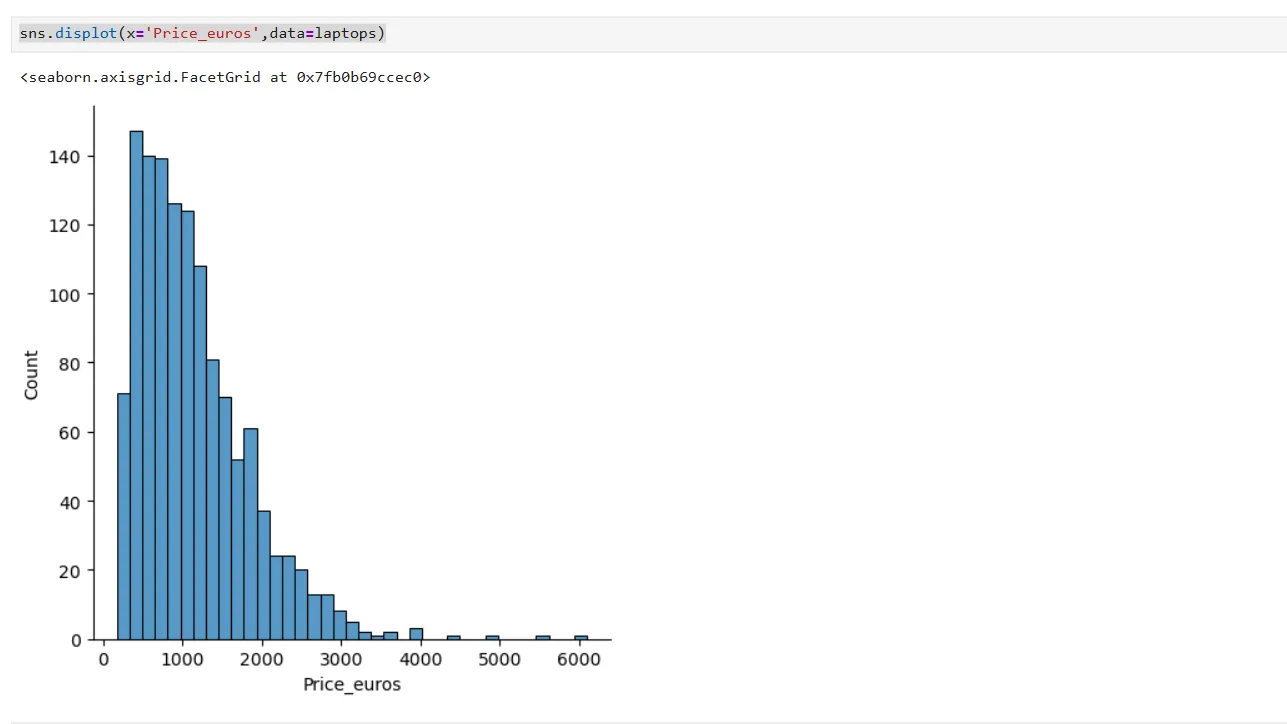 Biểu đồ histogram thể hiện sự phân bố giá laptop theo đơn vị Euro trong Jupyter Notebook, minh họa độ lệch phải của dữ liệu.
Biểu đồ histogram thể hiện sự phân bố giá laptop theo đơn vị Euro trong Jupyter Notebook, minh họa độ lệch phải của dữ liệu.
Biểu đồ này cho thấy giá laptop được phân bố trên trục x, sử dụng dữ liệu từ DataFrame laptops. Có thể thấy rõ phần đuôi của phân phối bị lệch đáng kể sang phải, cho thấy có nhiều laptop giá thấp hơn và một số ít laptop có giá rất cao.
Chúng ta sẽ xây dựng một mô hình sử dụng nhiều thông số kỹ thuật khác nhau. Mô hình sẽ có dạng như sau:
giá = a(tốc độ CPU) + b(RAM) + c(kích thước màn hình tính bằng inch) + …
Các chữ cái a, b, c là các hệ số được xác định bởi quá trình hồi quy. Mô hình này tương tự như hồi quy tuyến tính đơn giản mà bạn có thể đã thấy, nhưng thay vì khớp một đường thẳng trên biểu đồ tán xạ, chúng ta đang khớp một mặt phẳng. Vì mô hình này có nhiều hơn ba chiều, nó thực chất là một siêu mặt phẳng.
Để thu được hồi quy của giá (tính bằng Euro) so với kích thước màn hình, RAM, trọng lượng, chiều rộng màn hình, chiều cao màn hình, tần số CPU, bộ nhớ chính và bộ nhớ phụ của laptop, chúng ta sử dụng hàm hồi quy tuyến tính của Pingouin:
pg.linear_regression(laptops[['Inches','Ram','Weight','ScreenW','ScreenH','CPU_freq','PrimaryStorage','SecondaryStorage']],laptops['Price_euros'],relimp=True)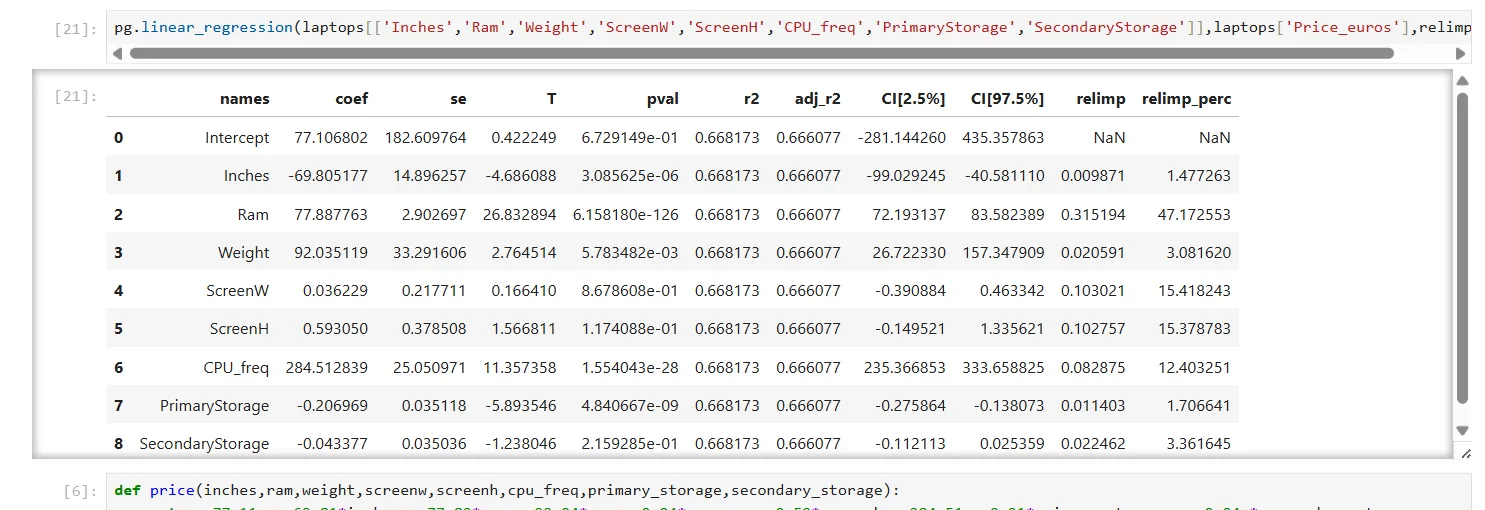 Kết quả mô hình hồi quy tuyến tính đa biến cho giá laptop trong Jupyter Notebook, hiển thị các hệ số hồi quy và độ phù hợp của mô hình (r2).
Kết quả mô hình hồi quy tuyến tính đa biến cho giá laptop trong Jupyter Notebook, hiển thị các hệ số hồi quy và độ phù hợp của mô hình (r2).
Lệnh này sẽ cung cấp các hệ số cho phương trình hồi quy. Tùy chọn relimp=True sẽ yêu cầu Pingouin tính toán mức độ đóng góp của mỗi biến vào giá. Các hệ số được hiển thị ở cột ngoài cùng bên trái, với cột ngoài cùng bên phải cho biết RAM là yếu tố dự đoán giá lớn nhất. Con số cần chú ý để đánh giá mức độ phù hợp của mô hình là bình phương hệ số tương quan, được ký hiệu là “r2” trong bảng này. Giá trị r2 của chúng ta là khoảng 0.66, cho thấy đây là một mô hình khá phù hợp.
Với các hệ số đã dự đoán, chúng ta có thể cắm các giá trị vào phương trình để dự đoán giá. Dưới đây là một hàm thực hiện điều đó:
def price(inches,ram,weight,screenw,screenh,cpu_freq,primary_storage,secondary_storage):
return 77.11 + -69.81*inches + 77.89*ram + 92.04*ram + 0.04*screenw + 0.59*screenh + 284.51 - 0.21*primary_storage + -0.04 * secondary_storage(Lưu ý: Dòng thứ hai của hàm cần được thụt lề trong mã Python thực tế.)
Giá có thực sự khác biệt giữa các thương hiệu?
Mô hình hồi quy chúng ta vừa xây dựng chỉ xem xét các thông số kỹ thuật. Tuy nhiên, bạn có thể tự hỏi liệu thương hiệu có phải là một yếu tố dự đoán giá đáng kể hay không. Chúng ta có thể sử dụng phân tích phương sai, hay ANOVA, để xác định xem sự khác biệt giữa các thương hiệu có ý nghĩa thống kê hay không. Vì dữ liệu giá bị lệch, như đã thấy trên biểu đồ histogram, một kiểm định phi tham số sẽ chính xác hơn. Pingouin cung cấp kiểm định Kruskal-Wallis để thực hiện việc này.
Kiểm định này sẽ kiểm tra giả thuyết không (null hypothesis) rằng không có mối quan hệ giữa giá và thương hiệu:
pg.kruskal(data=laptops,dv='Price_euros',between='Company').round(2) Kết quả kiểm định Kruskal-Wallis về ảnh hưởng của thương hiệu đến giá laptop bằng Python, cho thấy p-value rất nhỏ.
Kết quả kiểm định Kruskal-Wallis về ảnh hưởng của thương hiệu đến giá laptop bằng Python, cho thấy p-value rất nhỏ.
Kết quả cho thấy giá trị p-value là 0, điều này có nghĩa là yếu tố thương hiệu thực sự có ý nghĩa thống kê trong việc dự đoán giá. Việc làm tròn số được thực hiện để làm cho giá trị p-value rõ ràng hơn (nếu không, nó sẽ hiển thị dưới dạng ký hiệu khoa học). Kết quả này cho phép chúng ta bác bỏ giả thuyết không và kết luận rằng thương hiệu là một yếu tố dự đoán giá đáng kể.
Kết luận
Chúng tôi đã thành công trong việc xây dựng một mô hình dự đoán giá laptop, giúp xác định mức giá hợp lý dựa trên các thông số kỹ thuật của thiết bị. Đồng thời, chúng tôi cũng đã kiểm định và chứng minh rằng yếu tố thương hiệu có tác động đáng kể đến giá laptop. Điều này một lần nữa khẳng định sức mạnh của Python và các thư viện của nó trong việc biến một nhiệm vụ tưởng chừng khó khăn, tốn kém thời gian thành một vài dòng mã đơn giản.
Với những kiến thức và công cụ này, bạn có thể tự mình khám phá dữ liệu, xây dựng các mô hình dự đoán và đưa ra những quyết định sáng suốt hơn trong thế giới công nghệ luôn biến động. Hãy truy cập GitHub của chúng tôi để xem chi tiết mã nguồn và tự mình thử nghiệm! Bạn có bất kỳ câu hỏi hoặc ý kiến nào về mô hình này không? Hãy chia sẻ suy nghĩ của bạn ở phần bình luận bên dưới.